import requests
import os
import re
class BiliCoverSpider:
def __init__(self, id):
self.id = id
self.page = 1
self.user_url_format = 'https://api.bilibili.com/x/space/wbi/arc/search?mid={ID}&ps=30&tid=0&pn={PAGE}&keyword=&order=pubdate&order_avoided=true&w_rid=64a17313d0ab4fe3a74503517fe017b4&wts=1671862074'
self.data = []
def get_url(self, url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res = requests.get(url, headers=headers)
return res
def hundle_name(self, name):
name = name.replace(":", '')
name = name.replace("?", '')
name = name.replace("/", '')
name = name.replace("\\", '')
name = name.replace("|", '')
name = name.replace("<", '')
name = name.replace(">", '')
name = name.replace("*", '')
name = name.replace('"', '')
return name
def saveImageWithBv(self, url):
html = self.get_url(url)
r = re.search(r'//i\d.hdslb.com/bfs/archive/\w+.jpg', html.text)
imgurl = "https:" + html.text[r.span()[0]:r.span()[1]]
img = self.get_url(imgurl)
with open('1.jpg', 'wb') as f:
f.write(img.content)
def saveImage(self, url, title):
img = self.get_url(url)
with open(self.hundle_name(title) + '.jpg', 'wb') as f:
f.write(img.content)
def renewData(self):
user_url = self.user_url_format.format(ID=self.id, PAGE=self.page)
html = self.get_url(user_url)
self.data = html.json()['data']['list']['vlist']
def getAllCover(self):
self.renewData()
if len(self.data) == 0:
return
try:
os.mkdir(self.data[0]['author'])
os.chdir(self.data[0]['author'])
except:
os.chdir(self.data[0]['author'])
while (True):
if len(self.data) == 0:
return
for i in self.data:
print(i['pic'], i['title'])
self.saveImage(i['pic'], i['title'])
self.page += 1
self.renewData()
if __name__ == '__main__':
id = int(input("输入UID:"))
spy = BiliCoverSpider(id)
spy.getAllCover()
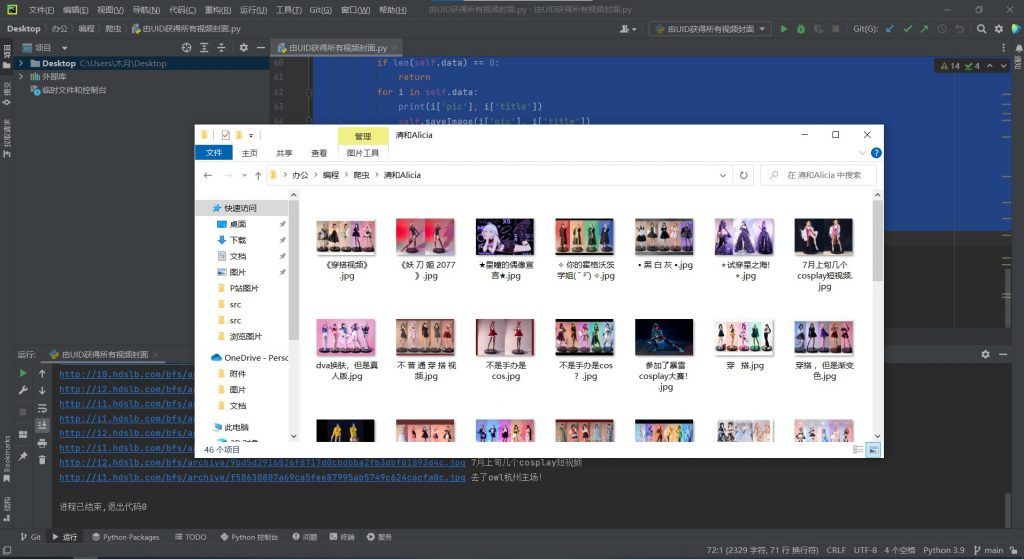
很好的文章,疯狂代码非常好的工作,爱来自波浪可爱